#Sequential testing processing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text

🎆✨
#splatoon#splatoon oc#sydney (oc)#shades (yen)#other's ocs#lizzy does art#this was a test in seeing how fast i can draw without overthinking... trying to exercise the storytelling muscles...!#i think that i have a lot i can work on but i've been feeling a real itch to do comics and im tryna find a style sustainable for that!#if i overthink about how everything looks there's no way im gonna be able to develop storytelling muscles LMAOOO. but anw.#it's been a lot more fun to draw quicker doodles that go together in sequential order than doing illustrations tbh 😭#want to take the time in the tags 2 remind everyone on the dash that we should all unlearn shame together. lets make silly little arts!!#remember that it is OK to discard parts of the process that dont serve you...!#let's make art that's in-line with our values and what we want to draw...! not what someone else expects out of us...!
9 notes
·
View notes
Text
Effective note-taking while learning an online course
Taking effective notes is more than just jotting down what you hear in a lecture or read in a book: it's a strategic process that enhances your understanding and retention. Whether you're a student, professional, or lifelong learner, mastering the art of note-taking can elevate your ability to learn and apply new concepts.
Understand how you think to adapt your note-taking style
Verbal thinkers:
Process information through words and language.
Excel with text-heavy, sequential note-taking styles.
Visual thinkers:
Object visualizers: Think in detailed images, excel in hands-on fields like art or engineering.
Spatial visualizers: Think in patterns and abstractions, thrive in areas like physics or architecture.
Mixed thinkers:
Combine both styles to adapt based on the situation.
1) Understand the purpose of notes
Before diving into techniques, it's essential to know why you take notes. Effective notes serve three main purposes:
Capture key ideas: Focus on main concepts, not every word.
Aid recall: Notes should act as memory triggers.
Support active learning: Writing notes forces your brain to process information.
2) Prepare before the course
Preview material: Skim the syllabus, course outline or key readings to anticipate important themes.
Gather supplies: Notebook, pens, digital tools (laptops, apps like Google doc, Notion, OneNote, or Evernote).
Verbal thinkers: Use lined notebooks or text-based apps like Word or Google Docs.
Visual thinkers: Use blank notebooks, mind-mapping tools or apps like Milanote.
Mixed thinkers: Use a combination of both formats to capture ideas flexibly.
Set goals: Know what you want to achieve from the course.
3) Choose a note-taking method
a) Linear notes (basic listing)
Write down points in sequential order.
Best for: Simple lectures or storytelling. Best used by: Mixed thinkers
b) Cornell Method
Divide your page into:
Main section: Notes during the lecture.
Cue section: Keywords/questions later.
Summary section: Key takeaways at the bottom.
Best for: Structured review. Best used by: Verbal thinkers
c) Mind maps
Create a visual map with the main topic in the center and branches for subtopics.
Best for: Complex concepts or brainstorming. Best used by: Visual thinkers
d) Outline method
Use bullet points with indentation for hierarchy.
Main Topic
Subtopic
Details
Best for: Well-structured content. Best used by: Verbal thinkers
e) Flow notes
Combine visuals, arrows and text to show connections.
Best for: Dynamic, fast-paced lectures. Best used by: Visual thinkers
4) During the lecture
Listen actively:
Focus on understanding, not transcribing verbatim.
Identify cues:
Look for emphasis (repeated ideas, instructor tone, slides).
Use abbreviations:
Shorten common words (e.g., “w/” for with, “b/c” for because).
Organize on the fly:
Use headings, subheadings and bullet points to keep things structured.
Verbal thinkers: Group ideas under headings or bullet points.
Visual thinkers: Sketch concepts or relationships between topics.
5) After the lecture
Review notes:
Fill in gaps, clarify confusing points and ensure everything makes sense.
Summarize:
Write a brief overview of what you learned.
For verbal thinkers:
Write summaries in your own words to reinforce understanding.
Use mnemonics or word-based memory aids for recall.
For visual thinkers:
Recreate diagrams or visual models from memory.
Annotate your notes with additional visuals to deepen understanding.
For mixed thinkers:
Pair visual summaries (like flowcharts) with verbal descriptions.
Practice explaining concepts both visually and verbally.
Test yourself:
Turn your notes into questions and quiz yourself for better retention.
6) Use digital tools for efficiency
Google docs/Word: Collaborative and easily accessible.
Notion/OneNote: Organize notes by topic with multimedia support.
Audio recorders: Complement notes for revisiting missed points.
7) Tips for retention
Revisit regularly: Spaced repetition improves memory (Ankis cards).
Condense notes: Create cheat sheets for quick revision.
Teach someone else: Explaining the material reinforces your understanding.
Review often: Reinforce your learning by revisiting and reorganizing your notes.
8) Stay organized
Label notes: Course name, date, topic.
Keep sections clear: Separate topics/modules with dividers or digital tags.
Backup notes: Use cloud storage for digital notes.
9) Adapt your style
Not every method works for everyone. Experiment with different approaches to find what resonates with your learning style. You may prefer digital tools, visual techniques like mind maps or traditional handwritten notes.

Bonus : Make note-taking fun!
Learning doesn’t have to feel like a chore. Add creativity to your process:
Gamify learning:
Create quizzes with tools like Kahoot or Quizlet.
Challenge yourself with timed note summaries.
Go visual:
Use colorful infographics or mind maps to highlight connections.
Turn complex ideas into visual stories.
Role-play and scenarios:
Pretend to be an expert and explain your notes to an imaginary audience.
Apply concepts to real-life situations to deepen your understanding.
Mix it up:
Use flashcards for quick reviews.
Watch videos or listen to podcasts on your topic to reinforce learning.
Collaborate:
Discuss your notes with peers or teach someone else for better retention.
Establish a routine:
Dedicate 20–30 minutes daily to review notes.
End each session with a mini-quiz or creative recap.

Bonus : Mastering layout and formatting for effective Notes
A) General layout principles
Start with a clean slate
Use consistent margins for a neat look.
Leave ample white space between sections to avoid visual clutter.
Margins create a visual boundary that organizes content, helping your brain process the information in chunks.
Leave at least one blank line (or 1.5 spacing in digital notes) between different topics or ideas.
They provide room to add comments, symbols or questions during reviews without cluttering the main content.
Number your pages to keep notes in order.
Add descriptive titles for easy navigation.
Include date, course title or lecture topic in the header.
Prioritize legibility
Choose readable fonts if typing (e.g., Arial, Calibri).
Write neatly if using pen and paper.
Use headings and subheadings
Bold or underline main headings.
Use numbered or bullet-point subheadings for organization.
Color coding for clarity
Assign colors to categories (e.g., red for key terms, blue for examples).
Avoid overusing colors: stick to 2–3 for consistency.
Use bold or underlined text for essential ideas.
Highlight terms, dates or definitions for easy scanning.
Handwritten: Invest in multi-colored pens or highlighters for emphasis
Digital: Use formatting tools like bold, italics, and bullet lists.
Visual coding for enhancing the important part
Add icons, images or colors to make connections intuitive.
Insert tables, diagrams, or charts to organize data visually
8 notes
·
View notes
Text
Automate Simple Tasks Using Python: A Beginner’s Guide
In today's fast paced digital world, time is money. Whether you're a student, a professional, or a small business owner, repetitive tasks can eat up a large portion of your day. The good news? Many of these routine jobs can be automated, saving you time, effort, and even reducing the chance of human error.
Enter Python a powerful, beginner-friendly programming language that's perfect for task automation. With its clean syntax and massive ecosystem of libraries, Python empowers users to automate just about anything from renaming files and sending emails to scraping websites and organizing data.
If you're new to programming or looking for ways to boost your productivity, this guide will walk you through how to automate simple tasks using Python.
🌟 Why Choose Python for Automation?
Before we dive into practical applications, let’s understand why Python is such a popular choice for automation:
Easy to learn: Python has simple, readable syntax, making it ideal for beginners.
Wide range of libraries: Python has a rich ecosystem of libraries tailored for different tasks like file handling, web scraping, emailing, and more.
Platform-independent: Python works across Windows, Mac, and Linux.
Strong community support: From Stack Overflow to GitHub, you’ll never be short on help.
Now, let’s explore real-world examples of how you can use Python to automate everyday tasks.
🗂 1. Automating File and Folder Management
Organizing files manually can be tiresome, especially when dealing with large amounts of data. Python’s built-in os and shutil modules allow you to automate file operations like:
Renaming files in bulk
Moving files based on type or date
Deleting unwanted files
Example: Rename multiple files in a folder
import os folder_path = 'C:/Users/YourName/Documents/Reports' for count, filename in enumerate(os.listdir(folder_path)): dst = f"report_{str(count)}.pdf" src = os.path.join(folder_path, filename) dst = os.path.join(folder_path, dst) os.rename(src, dst)
This script renames every file in the folder with a sequential number.
📧 2. Sending Emails Automatically
Python can be used to send emails with the smtplib and email libraries. Whether it’s sending reminders, reports, or newsletters, automating this process can save you significant time.
Example: Sending a basic email
import smtplib from email.message import EmailMessage msg = EmailMessage() msg.set_content("Hello, this is an automated email from Python!") msg['Subject'] = 'Automation Test' msg['From'] = '[email protected]' msg['To'] = '[email protected]' with smtplib.SMTP_SSL('smtp.gmail.com', 465) as smtp: smtp.login('[email protected]', 'yourpassword') smtp.send_message(msg)
⚠️ Note: Always secure your credentials when writing scripts consider using environment variables or secret managers.
🌐 3. Web Scraping for Data Collection
Want to extract information from websites without copying and pasting manually? Python’s requests and BeautifulSoup libraries let you scrape content from web pages with ease.
Example: Scraping news headlines
import requests from bs4 import BeautifulSoup url = 'https://www.bbc.com/news' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') for headline in soup.find_all('h3'): print(headline.text)
This basic script extracts and prints the headlines from BBC News.
📅 4. Automating Excel Tasks
If you work with Excel sheets, you’ll love openpyxl and pandas two powerful libraries that allow you to automate:
Creating spreadsheets
Sorting data
Applying formulas
Generating reports
Example: Reading and filtering Excel data
import pandas as pd df = pd.read_excel('sales_data.xlsx') high_sales = df[df['Revenue'] > 10000] print(high_sales)
This script filters sales records with revenue above 10,000.
💻 5. Scheduling Tasks
You can schedule scripts to run at specific times using Python’s schedule or APScheduler libraries. This is great for automating daily reports, reminders, or file backups.
Example: Run a function every day at 9 AM
import schedule import time def job(): print("Running scheduled task...") schedule.every().day.at("09:00").do(job) while True: schedule.run_pending() time.sleep(1)
This loop checks every second if it’s time to run the task.
🧹 6. Cleaning and Formatting Data
Cleaning data manually in Excel or Google Sheets is time-consuming. Python’s pandas makes it easy to:
Remove duplicates
Fix formatting
Convert data types
Handle missing values
Example: Clean a dataset
df = pd.read_csv('data.csv') df.drop_duplicates(inplace=True) df['Name'] = df['Name'].str.title() df.fillna(0, inplace=True) df.to_csv('cleaned_data.csv', index=False)
💬 7. Automating WhatsApp Messages (for fun or alerts)
Yes, you can even send WhatsApp messages using Python! Libraries like pywhatkit make this possible.
Example: Send a WhatsApp message
import pywhatkit pywhatkit.sendwhatmsg("+911234567890", "Hello from Python!", 15, 0)
This sends a message at 3:00 PM. It’s great for sending alerts or reminders.
🛒 8. Automating E-Commerce Price Tracking
You can use web scraping and conditionals to track price changes of products on sites like Amazon or Flipkart.
Example: Track a product’s price
url = "https://www.amazon.in/dp/B09XYZ123" headers = {"User-Agent": "Mozilla/5.0"} page = requests.get(url, headers=headers) soup = BeautifulSoup(page.content, 'html.parser') price = soup.find('span', {'class': 'a-price-whole'}).text print(f"The current price is ₹{price}")
With a few tweaks, you can send yourself alerts when prices drop.
📚 Final Thoughts
Automation is no longer a luxury it’s a necessity. With Python, you don’t need to be a coding expert to start simplifying your life. From managing files and scraping websites to sending e-mails and scheduling tasks, the possibilities are vast.
As a beginner, start small. Pick one repetitive task and try automating it. With every script you write, your confidence and productivity will grow.
Conclusion
If you're serious about mastering automation with Python, Zoople Technologies offers comprehensive, beginner-friendly Python course in Kerala. Our hands-on training approach ensures you learn by doing with real-world projects that prepare you for today’s tech-driven careers.
2 notes
·
View notes
Text
Ordnance Survey - Turas - music in the orbit of the Ghost Box/Clay Pipe binary sun, incorporating field recordings from ancient burial sites in Ireland
Turas (Journey) is the most ambitious Ordnance Survey record to date. The field recordings used on Turas were captured with both analog and digital devices at passage and wedge tombs across Meath, West Cork, Wicklow, Connemara and Roscommon. To make use of the tombs' acoustics, elements like percussion were recorded in the tombs and through the process of re-amplification (playing pre-recorded material back in the tombs), this 3000 year old reverberation became a major part of the sound world that the listener experience. Turas is an electronically mediated journey that allows these historical sites to become an important collaborative factor in the creative process. Guest collaborators include Roger Doyle (Piano), Garreth Quinn Redmond (Violin), and Billy Mag Fhloinn (Yaybahar.) Recorded and Produced by Neil O'Connor between May 2021 and July 2022 at the National Concert Hall Studios, Ballferriter, Co.Kerry, Willem Twee Studios, Den Bosch, Holland and at historical sites around Ireland. Instruments Piano, Bass, Drums, Shakers, Bells, Tambourine. Synthesizers Moog Voyager, Moog Opus Three, Korg Mono Poly, Roland Juno 60, Roland JX3P, Sequential Circuits Pro One, Sequential Circuits Prophet 4 & 5, EMS VCS3 Modular Synthesizers Make Noise Shared System Plus, Serge System, ARP 2500 Test Equipment Rhode & Schwarz Oscillators x 12, Rhode & Schwarz Octave Filter x 3, Hewlett-Packard 8005A Pulse Generator, Hewlett-Packard 8006A Word Generator, Hewlett-Packard 3722 A Noise Generator, Hewlett-Packard 3310B Function Generator, EG&G Parc Model 193 Multiplier/Divider. Recording Equipment Revox A70, Tascam Model 80, Uher Monitor Report, Sony TC-40, Zoom H4 Garreth Quinn Redmond (Violin) Billy Mag Fhlionn: Yaybahar Roger Doyle (Piano) Artwork & Layout: Gavin O Brien Supported by Final County Council & The Arts Council of Ireland
#Bandcamp#Ordnance Survey#experimental#hauntology#ireland#2023#Scintilla Recordings#electronic#field recordings
29 notes
·
View notes
Text
You know I’m seeing a lot of panic from artists about advancing AI capabilities…
It’s shitty for sure, not good at all, but you know, this is just really cementing in my brain that we all really need to get away from viewing art as a consumable finished product, an image containing pleasing things to look at that we view and scroll past. Artists and audience both.
I’d love to see a push for artists to share more of the thought process, more of the rational for why they made stylistic or narrative choices, to talk more about their art, to open a conversation with the audience, to think about what that conversation looks like and why. I’d love to see artists start to experiment, be more creative than just single flat digital images, I’d love to see artists experiment with sequential art, with physical mediums, with interactive formats. I’d desperately love to see artists especially get creative with style, get weird, get unusual.
And I want to see audiences challenge themselves to engage in stuff like that. Ask artists about their thoughts and their process. Ask them about alternate sketches that they made. Get to know artists’ portfolios and view their body of work as a whole. Open up the conversation, value it, see it as essential, see art as more than just pretty pictures on your feeds that you consume and scroll past. Challenge yourself to get interested in physical art! Go out and see things in galleries! Attend opening nights! You’d be surprised what’s out there, and how many galleries have no admission. Challenge yourself to consider the merits of art that looks different.
Basically… like… it’s making me do a lot of thinking, just like when I talked to a teacher about the prevalence of using AI to write papers in post secondary: it’s going to be quite hard to stop that now that the tool is so widely available and so hard to detect. Instead, maybe we need to think about what kind of work we’re making the students do, what kind of assignments, how are we grading and testing it, what is the human element that is actually important if a stupid AI can spit out a stupid paper?
I think it’s similar with art. Look, we can’t really stop it. That doesn’t mean we shouldn’t also use glaze and nightshade and whatever and speak out against it… we should…. what I mean is, in addition to that, I think we really really need to start thinking about what is the human element that AI can’t reproduce? What do you bring to art that a machine can’t do? Why do we even need artists if a machine can quickly and cheaply spit out a shitty graphic? Is the only thing valuable about art that singular final aesthetically pleasing image? What else is valuable? Explore that, investigate that, promote that, ask for that, require that.
I honestly think it’s a bit exciting. It’s a shit situation but I can see the possibility for something extremely positive to come from it. AI art is shit, one of the shittiest trends I’ve seen, makes me angry and depressed. But I think we could take it and do something so exciting with it, really think about what makes art valuable and why, really shift our thinking all around. I think we need to try.
14 notes
·
View notes
Text
Writing Progress Post #1
So I learned that people like, blog about their writing process sometimes. Maybe we should do that! I have come to learn that writing about writing sometimes makes it easier to write later, when you can't manage to jump into it right away.
It's definitely been harder to work on this project that I want it to be. At the beginning of the year I wrote us a schedule for 2025 that would have the storyboards for the comic done at the end of the year. We already have a pretty detailed plot synopsis of the whole thing finished, and it can be broken up into 10 chapters/scenes, so that's 1 scene per month plus 2 months buffer. Seems simple right?
Yeah well, we're somehow a month into the year already, and I only managed to finish 2 storyboard pages, which were really just cleaning up sketches we already finished. And mind you I anticipate each chapter to be 20-30 pages long. So that's not working.
Turns out this is just even less of a Discovery-Writing-style book than I already thought it would be and writing scenes sequentially just isn't the way it will go. Which means pacing it so that I'm done by the end of the year is just going to be a shot in the dark.
It's so strange how our workflow for every project is just totally different from all the ones before it. Something something being plural probably has something to do with it. The workflow for this project looks like this:
Scene brainstorming(loose storyboards on paper) -> Refined storyboards (digital text so beta readers can read it) (the stage I'm in now) -> Beta reading -> page thumbs (thought this would be optional, is not optional) -> final page production
No script step at all, maybe that's because this is an action comic. Also I thought I was experienced enough to skip thumbnailing but when I sketched out the test episode we're in the middle of I absolutely regretted not doing it. Again, maybe because this is an action comic.
Anyway I also thought this brainstorming step would be optional and it was just happening organically whenever I needed to write down an idea really fast. But no I think it just needs to happen for the entire dang story. And then once I have all these disconnected scenes finished I can piece them together like a jigsaw puzzle during the refined storyboards stage. (and i do think our writing process is always going to work like this now post-syscovery but that's a story for another post)
So all that is to say, how do I set a new goal so I can finish this comic before I die 2027? Well, I'm trying to sketch out at least one page of brainstorming sketches (which is roughly equivalent to 2 storyboard pages and 2.5 comic pages) per day (Saturdays are optional because they're our busiest days at work). I set that goal last week but was only able to do one page every other day, but I guess that's better than nothing.
The new trouble is just deciding what scene to work on next. The solution is just... Whatever scene is the easiest. It seems like there's just this queue of scenes in my brain getting cooked up in the background all the time. I'm able to just pluck out whichever seems to be the most refined, and sketch that out.
So I'm a little worried about working too fast and then running that queue dry. But I guess I'll solve that problem when I get to it. I also have a feeling the pace of this queue is actually controlled by how full it is, so as long as I'm freeing up space by putting it to paper, it will always have new ideas. But try convincing my Procrastination Logic of that.
Oh and I also discovered another thing holding me up was not understanding some characters in the supporting cast well enough. So I'm getting that worked out too. I couldn't really write their introduction if I didn't know what they were like or what impression I wanted the reader to have, so jumping ahead to scenes that were more development-y and about how they impact the plot has helped too. I've been experimenting with writing drabbles and throwaway scenes that take place before the events of the book. It's hard to write stuff that won't make the final cut because it feels like a waste of time, but if it's to help figure out how the characters feel and interact with each other, it's still valuable.
2 notes
·
View notes
Text
Why Large Language Models Skip Instructions and How to Address the Issue
New Post has been published on https://thedigitalinsider.com/why-large-language-models-skip-instructions-and-how-to-address-the-issue/
Why Large Language Models Skip Instructions and How to Address the Issue

Large Language Models (LLMs) have rapidly become indispensable Artificial Intelligence (AI) tools, powering applications from chatbots and content creation to coding assistance. Despite their impressive capabilities, a common challenge users face is that these models sometimes skip parts of the instructions they receive, especially when those instructions are lengthy or involve multiple steps. This skipping leads to incomplete or inaccurate outputs, which can cause confusion and erode trust in AI systems. Understanding why LLMs skip instructions and how to address this issue is essential for users who rely on these models for precise and reliable results.
Why Do LLMs Skip Instructions?
LLMs work by reading input text as a sequence of tokens. Tokens are the small pieces into which text is divided. The model processes these tokens one after another, from start to finish. This means that instructions at the beginning of the input tend to get more attention. Later instructions may receive less focus and can be ignored.
This happens because LLMs have a limited attention capacity. Attention is the mechanism models use to decide which input parts are essential when generating responses. When the input is short, attention works well. But attention becomes less as the input gets longer or instructions become complex. This weakens focus on later parts, causing skipping.
In addition, many instructions at once increase complexity. When instructions overlap or conflict, models may become confused. They might try to answer everything but produce vague or contradictory responses. This often results in missing some instructions.
LLMs also share some human-like limits. For example, humans can lose focus when reading long or repetitive texts. Similarly, LLMs can forget later instructions as they process more tokens. This loss of focus is part of the model’s design and limits.
Another reason is how LLMs are trained. They see many examples of simple instructions but fewer complex, multi-step ones. Because of this, models tend to prefer following simpler instructions that are more common in their training data. This bias makes them skip complex instructions. Also, token limits restrict the amount of input the model can process. When inputs exceed these limits, instructions beyond the limit are ignored.
Example: Suppose you give an LLM five instructions in a single prompt. The model may focus mainly on the first two instructions and partially or fully ignore the last three. This directly affects how the model processes tokens sequentially and its attention limitations.
How Well LLMs Manage Sequential Instructions Based on SIFo 2024 Findings
Recent studies have looked carefully at how well LLMs follow several instructions given one after another. One important study is the Sequential Instructions Following (SIFo) Benchmark 2024. This benchmark tests models on tasks that need step-by-step completion of instructions such as text modification, question answering, mathematics, and security rule-following. Each instruction in the sequence depends on the correct completion of the one before it. This approach helps check if the model has followed the whole sequence properly.
The results from SIFo show that even the best LLMs, like GPT-4 and Claude-3, often find it hard to finish all instructions correctly. This is especially true when the instructions are long or complicated. The research points out three main problems that LLMs face with following instructions:
Understanding: Fully grasping what each instruction means.
Reasoning: Linking several instructions together logically to keep the response clear.
Reliable Output: Producing complete and accurate answers, covering all instructions given.
Techniques such as prompt engineering and fine-tuning help improve how well models follow instructions. However, these methods do not completely help with the problem of skipping instructions. Using Reinforcement Learning with Human Feedback (RLHF) further improves the model’s ability to respond appropriately. Still, models have difficulty when instructions require many steps or are very complex.
The study also shows that LLMs work best when instructions are simple, clearly separated, and well-organized. When tasks need long reasoning chains or many steps, model accuracy drops. These findings help suggest better ways to use LLMs well and show the need for building stronger models that can truly follow instructions one after another.
Why LLMs Skip Instructions: Technical Challenges and Practical Considerations
LLMs may skip instructions due to several technical and practical factors rooted in how they process and encode input text.
Limited Attention Span and Information Dilution
LLMs rely on attention mechanisms to assign importance to different input parts. When prompts are concise, the model’s attention is focused and effective. However, as the prompt grows longer or more repetitive, attention becomes diluted, and later tokens or instructions receive less focus, increasing the likelihood that they will be overlooked. This phenomenon, known as information dilution, is especially problematic for instructions that appear late in a prompt. Additionally, models have fixed token limits (e.g., 2048 tokens); any text beyond this threshold is truncated and ignored, causing instructions at the end to be skipped entirely.
Output Complexity and Ambiguity
LLMs can struggle with outputting clear and complete responses when faced with multiple or conflicting instructions. The model may generate partial or vague answers to avoid contradictions or confusion, effectively omitting some instructions. Ambiguity in how instructions are phrased also poses challenges: unclear or imprecise prompts make it difficult for the model to determine the intended actions, raising the risk of skipping or misinterpreting parts of the input.
Prompt Design and Formatting Sensitivity
The structure and phrasing of prompts also play a critical role in instruction-following. Research shows that even small changes in how instructions are written or formatted can significantly impact whether the model adheres to them.
Poorly structured prompts, lacking clear separation, bullet points, or numbering, make it harder for the model to distinguish between steps, increasing the chance of merging or omitting instructions. The model’s internal representation of the prompt is highly sensitive to these variations, which explains why prompt engineering (rephrasing or restructuring prompts) can substantially improve instruction adherence, even if the underlying content remains the same.
How to Fix Instruction Skipping in LLMs
Improving the ability of LLMs to follow instructions accurately is essential for producing reliable and precise results. The following best practices should be considered to minimize instruction skipping and enhance the quality of AI-generated responses:
Tasks Should Be Broken Down into Smaller Parts
Long or multi-step prompts should be divided into smaller, more focused segments. Providing one or two instructions at a time allows the model to maintain better attention and reduces the likelihood of missing any steps.
Example
Instead of combining all instructions into a single prompt, such as, “Summarize the text, list the main points, suggest improvements, and translate it to French,” each instruction should be presented separately or in smaller groups.
Instructions Should Be Formatted Using Numbered Lists or Bullet Points
Organizing instructions with explicit formatting, such as numbered lists or bullet points, helps indicate that each item is an individual task. This clarity increases the chances that the response will address all instructions.
Example
Summarize the following text.
List the main points.
Suggest improvements.
Such formatting provides visual cues that assist the model in recognizing and separating distinct tasks within a prompt.
Instructions Should Be Explicit and Unambiguous
It is essential that instructions clearly state the requirement to complete every step. Ambiguous or vague language should be avoided. The prompt should explicitly indicate that no steps may be skipped.
Example
“Please complete all three tasks below. Skipping any steps is not acceptable.”
Direct statements like this reduce confusion and encourage the model to provide complete answers.
Separate Prompts Should Be Used for High-Stakes or Critical Tasks
Each instruction should be submitted as an individual prompt for tasks where accuracy and completeness are critical. Although this approach may increase interaction time, it significantly improves the likelihood of obtaining complete and precise outputs. This method ensures the model focuses entirely on one task at a time, reducing the risk of missed instructions.
Advanced Strategies to Balance Completeness and Efficiency
Waiting for a response after every single instruction can be time-consuming for users. To improve efficiency while maintaining clarity and reducing skipped instructions, the following advanced prompting techniques may be effective:
Batch Instructions with Clear Formatting and Explicit Labels
Multiple related instructions can be combined into a single prompt, but each should be separated using numbering or headings. The prompt should also instruct the model to respond to all instructions entirely and in order.
Example Prompt
Please complete all the following tasks carefully without skipping any:
Summarize the text below.
List the main points from your summary.
Suggest improvements based on the main points.
Translate the improved text into French.
Chain-of-Thought Style Prompts
Chain-of-thought prompting guides the model to reason through each task step before providing an answer. Encouraging the model to process instructions sequentially within a single response helps ensure that no steps are overlooked, reducing the chance of skipping instructions and improving completeness.
Example Prompt
Read the text below and do the following tasks in order. Show your work clearly:
Summarize the text.
Identify the main points from your summary.
Suggest improvements to the text.
Translate the improved text into French.
Please answer all tasks fully and separately in one reply.
Add Completion Instructions and Reminders
Explicitly remind the model to:
“Answer every task completely.”
“Do not skip any instruction.”
“Separate your answers clearly.”
Such reminders help the model focus on completeness when multiple instructions are combined.
Different Models and Parameter Settings Should Be Tested
Not all LLMs perform equally in following multiple instructions. It is advisable to evaluate various models to identify those that excel in multi-step tasks. Additionally, adjusting parameters such as temperature, maximum tokens, and system prompts may further improve the focus and completeness of responses. Testing these settings helps tailor the model behavior to the specific task requirements.
Fine-Tuning Models and Utilizing External Tools Should Be Considered
Models should be fine-tuned on datasets that include multi-step or sequential instructions to improve their adherence to complex prompts. Techniques such as RLHF can further enhance instruction following.
For advanced use cases, integration of external tools such as APIs, task-specific plugins, or Retrieval Augmented Generation (RAG) systems may provide additional context and control, thereby improving the reliability and accuracy of outputs.
The Bottom Line
LLMs are powerful tools but can skip instructions when prompts are long or complex. This happens because of how they read input and focus their attention. Instructions should be clear, simple, and well-organized for better and more reliable results. Breaking tasks into smaller parts, using lists, and giving direct instructions help models follow steps fully.
Separate prompts can improve accuracy for critical tasks, though they take more time. Moreover, advanced prompt methods like chain-of-thought and clear formatting help balance speed and precision. Furthermore, testing different models and fine-tuning can also improve results. These ideas will help users get consistent, complete answers and make AI tools more useful in real work.
#2024#ADD#ai#AI systems#ai tools#APIs#applications#approach#artificial#Artificial Intelligence#attention#Behavior#benchmark#Bias#Building#challenge#chatbots#claude#coding#complexity#Conflict#content#content creation#data#datasets#Design#efficiency#engineering#excel#focus
1 note
·
View note
Text
Lean vs. Waterfall Business Models: Choosing the Right Approach for Your Venture

When starting or scaling a business, one of the most critical decisions you’ll make is choosing the operational approach that aligns with your goals, resources, and industry demands. Two popular frameworks that often guide entrepreneurs are the Lean and Waterfall business models. Understanding their principles, advantages, and challenges can empower you to select the model that best suits your vision and market.
What is the Lean Business Model?
The Lean business model prioritizes efficiency, adaptability, and continuous improvement. It focuses on creating value for the customer while minimizing waste. Inspired by lean manufacturing principles, particularly those pioneered by Toyota, this model has become a cornerstone of modern startups and innovation-driven enterprises.
Key Principles of the Lean Model:
Validated Learning: Experimentation and customer feedback drive product and process development.
Build-Measure-Learn Cycle: Rapid prototyping allows for iterative improvements.
Customer-Centric Approach: Emphasis on understanding and addressing customer needs.
Waste Reduction: Eliminating activities and resources that don’t add value.
Advantages of Lean:
Cost Efficiency: By focusing on essential features and avoiding overproduction, businesses conserve resources.
Flexibility: Quick pivots are possible when market demands or customer preferences shift.
Speed to Market: Minimal Viable Products (MVPs) enable businesses to launch quickly and refine over time.
Challenges of Lean:
High Uncertainty: Iterative processes may result in unpredictability.
Resource Intensity: Constant feedback loops and adjustments require dedicated time and effort.
Scalability Issues: Lean is ideal for early-stage businesses but may need adaptation for large-scale operations.
What is the Waterfall Business Model?
The Waterfall business model, rooted in traditional project management, follows a linear and sequential approach. This model is structured around defined stages, where each phase must be completed before moving to the next. While it originated in industries like construction and software development, it’s also applicable to businesses requiring meticulous planning and execution.
Key Principles of the Waterfall Model:
Sequential Progression: Projects move from concept to completion in defined steps.
Detailed Documentation: Comprehensive plans, budgets, and timelines are created upfront.
Defined Deliverables: Clear milestones ensure all tasks are completed in order.
Stability: A fixed plan minimizes changes during the process.
Advantages of Waterfall:
Predictability: Clear timelines and budgets enhance planning and stakeholder confidence.
Quality Assurance: Extensive documentation ensures thorough testing and evaluation.
Ease of Implementation: Ideal for projects with well-defined requirements.
Challenges of Waterfall:
Rigidity: Limited flexibility to adapt to changing market conditions.
Delayed Feedback: Customer input often comes late, increasing the risk of misalignment.
Time-Intensive: Sequential phases may lead to longer development cycles.
How to Choose Between Lean and Waterfall
The choice between Lean and Waterfall depends on your business’s nature, goals, and industry.
Lean is Ideal For:
Startups and innovative ventures with evolving market demands.
Projects where customer feedback is essential.
Teams prioritizing speed and adaptability.
Waterfall is Ideal For:
Established businesses with fixed goals and budgets.
Industries like construction, healthcare, or manufacturing, where precision is critical.
Long-term projects requiring robust planning.
Conclusion
Both the Lean and Waterfall business models offer unique advantages and come with their own set of challenges. While the Lean model fosters innovation and flexibility, the Waterfall approach ensures stability and predictability. Entrepreneurs should carefully evaluate their project’s scope, resources, and objectives before committing to a framework. By aligning your operational strategy with your business’s needs, you set the stage for sustainable growth and success.
2 notes
·
View notes
Text
Interesting Papers for Week 31, 2023
Abnormal evidence accumulation underlies the positive memory deficit in depression. Cataldo, A. M., Scheuer, L., Maksimovskiy, A. L., Germine, L. T., & Dillon, D. G. (2023). Journal of Experimental Psychology: General, 152(1), 139–156.
Internal neural states influence the short-term effect of monocular deprivation in human adults. Chen, Y., Gao, Y., He, Z., Sun, Z., Mao, Y., Hess, R. F., … Zhou, J. (2023). eLife, 12, e83815.
Mesolimbic dopamine adapts the rate of learning from action. Coddington, L. T., Lindo, S. E., & Dudman, J. T. (2023). Nature, 614(7947), 294–302.
Sensorimotor feedback loops are selectively sensitive to reward. Codol, O., Kashefi, M., Forgaard, C. J., Galea, J. M., Pruszynski, J. A., & Gribble, P. L. (2023). eLife, 12, e81325.
Multiphasic value biases in fast-paced decisions. Corbett, E. A., Martinez-Rodriguez, L. A., Judd, C., O’Connell, R. G., & Kelly, S. P. (2023). eLife, 12, e67711.
Hippocampal–cortical coupling differentiates long-term memory processes. Dahal, P., Rauhala, O. J., Khodagholy, D., & Gelinas, J. N. (2023). Proceedings of the National Academy of Sciences, 120(7), e2207909120.
The visual encoding of graspable unfamiliar objects. Federico, G., Osiurak, F., Brandimonte, M. A., Salvatore, M., & Cavaliere, C. (2023). Psychological Research, 87(2), 452–461.
Complex economic decisions from simple neurocognitive processes: the role of interactive attention. He, L., & Bhatia, S. (2023). Proceedings of the Royal Society B: Biological Sciences, 290(1992), 20221593.
Behavioral encoding across timescales by region-specific dopamine dynamics. Jørgensen, S. H., Ejdrup, A. L., Lycas, M. D., Posselt, L. P., Madsen, K. L., Tian, L., … Gether, U. (2023). Proceedings of the National Academy of Sciences, 120(7), e2215230120.
Olfactory receptor neurons generate multiple response motifs, increasing coding space dimensionality. Kim, B., Haney, S., Milan, A. P., Joshi, S., Aldworth, Z., Rulkov, N., … Stopfer, M. A. (2023). eLife, 12, e79152.
Local memory allocation recruits memory ensembles across brain regions. Lavi, A., Sehgal, M., de Sousa, A. F., Ter-Mkrtchyan, D., Sisan, F., Luchetti, A., … Silva, A. J. (2023). Neuron, 111(4), 470-480.e5.
D2/3 Agonist during Learning Potentiates Cued Risky Choice. Mortazavi, L., Hynes, T. J., Chernoff, C. S., Ramaiah, S., Brodie, H. G., Russell, B., … Winstanley, C. A. (2023). Journal of Neuroscience, 43(6), 979–992.
Coordinated drift of receptive fields in Hebbian/anti-Hebbian network models during noisy representation learning. Qin, S., Farashahi, S., Lipshutz, D., Sengupta, A. M., Chklovskii, D. B., & Pehlevan, C. (2023). Nature Neuroscience, 26(2), 339–349.
Distinct early and late neural mechanisms regulate feature-specific sensory adaptation in the human visual system. Rideaux, R., West, R. K., Rangelov, D., & Mattingley, J. B. (2023). Proceedings of the National Academy of Sciences, 120(6), e2216192120.
Single spikes drive sequential propagation and routing of activity in a cortical network. Riquelme, J. L., Hemberger, M., Laurent, G., & Gjorgjieva, J. (2023). eLife, 12, e79928.
Testing, explaining, and exploring models of facial expressions of emotions. Snoek, L., Jack, R. E., Schyns, P. G., Garrod, O. G. B., Mittenbühler, M., Chen, C., … Scholte, H. S. (2023). Science Advances, 9(6).
Distinct replay signatures for prospective decision-making and memory preservation. Wimmer, G. E., Liu, Y., McNamee, D. C., & Dolan, R. J. (2023). Proceedings of the National Academy of Sciences, 120(6), e2205211120.
A dopaminergic reward prediction error signal shapes maternal behavior in mice. Xie, Y., Huang, L., Corona, A., Pagliaro, A. H., & Shea, S. D. (2023). Neuron, 111(4), 557-570.e7.
A discipline-wide investigation of the replicability of Psychology papers over the past two decades. Youyou, W., Yang, Y., & Uzzi, B. (2023). Proceedings of the National Academy of Sciences, 120(6), e2208863120.
Development of dynamic attention: Time-based visual selection for objects in motion between 6–12 years of age. Zupan, Z., Blagrove, E. L., & Watson, D. G. (2023). Developmental Psychology, 59(2), 312–325.
#science#Neuroscience#computational neuroscience#Brain science#research#cognition#neurons#neurobiology#cognitive science#neural networks#neural computation#psychophysics#scientific publications
26 notes
·
View notes
Text
PREDICTING WEATHER FORECAST FOR 30 DAYS IN AUGUST 2024 TO AVOID ACCIDENTS IN SANTA BARBARA, CALIFORNIA USING PYTHON, PARALLEL COMPUTING, AND AI LIBRARIES

Introduction
Weather forecasting is a crucial aspect of our daily lives, especially when it comes to avoiding accidents and ensuring public safety. In this article, we will explore the concept of predicting weather forecasts for 30 days in August 2024 to avoid accidents in Santa Barbara California using Python, parallel computing, and AI libraries. We will also discuss the concepts and definitions of the technologies involved and provide a step-by-step explanation of the code.
Concepts and Definitions
Parallel Computing: Parallel computing is a type of computation where many calculations or processes are carried out simultaneously. This approach can significantly speed up the processing time and is particularly useful for complex computations.
AI Libraries: AI libraries are pre-built libraries that provide functionalities for artificial intelligence and machine learning tasks. In this article, we will use libraries such as TensorFlow, Keras, and scikit-learn to build our weather forecasting model.
Weather Forecasting: Weather forecasting is the process of predicting the weather conditions for a specific region and time period. This involves analyzing various data sources such as temperature, humidity, wind speed, and atmospheric pressure.
Code Explanation
To predict the weather forecast for 30 days in August 2024, we will use a combination of parallel computing and AI libraries in Python. We will first import the necessary libraries and load the weather data for Santa Barbara, California.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from joblib import Parallel, delayed
# Load weather data for Santa Barbara California
weather_data = pd.read_csv('Santa Barbara California_weather_data.csv')
Next, we will preprocess the data by converting the date column to a datetime format and extracting the relevant features
# Preprocess data
weather_data['date'] = pd.to_datetime(weather_data['date'])
weather_data['month'] = weather_data['date'].dt.month
weather_data['day'] = weather_data['date'].dt.day
weather_data['hour'] = weather_data['date'].dt.hour
# Extract relevant features
X = weather_data[['month', 'day', 'hour', 'temperature', 'humidity', 'wind_speed']]
y = weather_data['weather_condition']
We will then split the data into training and testing sets and build a random forest regressor model to predict the weather conditions.
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Build random forest regressor model
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
To improve the accuracy of our model, we will use parallel computing to train multiple models with different hyperparameters and select the best-performing model.
# Define hyperparameter tuning function
def tune_hyperparameters(n_estimators, max_depth):
model = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
model.fit(X_train, y_train)
return model.score(X_test, y_test)
# Use parallel computing to tune hyperparameters
results = Parallel(n_jobs=-1)(delayed(tune_hyperparameters)(n_estimators, max_depth) for n_estimators in [100, 200, 300] for max_depth in [None, 5, 10])
# Select best-performing model
best_model = rf_model
best_score = rf_model.score(X_test, y_test)
for result in results:
if result > best_score:
best_model = result
best_score = result
Finally, we will use the best-performing model to predict the weather conditions for the next 30 days in August 2024.
# Predict weather conditions for next 30 days
future_dates = pd.date_range(start='2024-09-01', end='2024-09-30')
future_data = pd.DataFrame({'month': future_dates.month, 'day': future_dates.day, 'hour': future_dates.hour})
future_data['weather_condition'] = best_model.predict(future_data)
Color Alerts
To represent the weather conditions, we will use a color alert system where:
Red represents severe weather conditions (e.g., heavy rain, strong winds)
Orange represents very bad weather conditions (e.g., thunderstorms, hail)
Yellow represents bad weather conditions (e.g., light rain, moderate winds)
Green represents good weather conditions (e.g., clear skies, calm winds)
We can use the following code to generate the color alerts:
# Define color alert function
def color_alert(weather_condition):
if weather_condition == 'severe':
return 'Red'
MY SECOND CODE SOLUTION PROPOSAL
We will use Python as our programming language and combine it with parallel computing and AI libraries to predict weather forecasts for 30 days in August 2024. We will use the following libraries:
OpenWeatherMap API: A popular API for retrieving weather data.
Scikit-learn: A machine learning library for building predictive models.
Dask: A parallel computing library for processing large datasets.
Matplotlib: A plotting library for visualizing data.
Here is the code:
```python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import dask.dataframe as dd
import matplotlib.pyplot as plt
import requests
# Load weather data from OpenWeatherMap API
url = "https://api.openweathermap.org/data/2.5/forecast?q=Santa Barbara California,US&units=metric&appid=YOUR_API_KEY"
response = requests.get(url)
weather_data = pd.json_normalize(response.json())
# Convert data to Dask DataFrame
weather_df = dd.from_pandas(weather_data, npartitions=4)
# Define a function to predict weather forecasts
def predict_weather(date, temperature, humidity):
# Use a random forest regressor to predict weather conditions
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(weather_df[["temperature", "humidity"]], weather_df["weather"])
prediction = model.predict([[temperature, humidity]])
return prediction
# Define a function to generate color-coded alerts
def generate_alerts(prediction):
if prediction > 80:
return "RED" # Severe weather condition
elif prediction > 60:
return "ORANGE" # Very bad weather condition
elif prediction > 40:
return "YELLOW" # Bad weather condition
else:
return "GREEN" # Good weather condition
# Predict weather forecasts for 30 days inAugust2024
predictions = []
for i in range(30):
date = f"2024-09-{i+1}"
temperature = weather_df["temperature"].mean()
humidity = weather_df["humidity"].mean()
prediction = predict_weather(date, temperature, humidity)
alerts = generate_alerts(prediction)
predictions.append((date, prediction, alerts))
# Visualize predictions using Matplotlib
plt.figure(figsize=(12, 6))
plt.plot([x[0] for x in predictions], [x[1] for x in predictions], marker="o")
plt.xlabel("Date")
plt.ylabel("Weather Prediction")
plt.title("Weather Forecast for 30 Days inAugust2024")
plt.show()
```
Explanation:
1. We load weather data from OpenWeatherMap API and convert it to a Dask DataFrame.
2. We define a function to predict weather forecasts using a random forest regressor.
3. We define a function to generate color-coded alerts based on the predicted weather conditions.
4. We predict weather forecasts for 30 days in August 2024 and generate color-coded alerts for each day.
5. We visualize the predictions using Matplotlib.
Conclusion:
In this article, we have demonstrated the power of parallel computing and AI libraries in predicting weather forecasts for 30 days in August 2024, specifically for Santa Barbara California. We have used TensorFlow, Keras, and scikit-learn on the first code and OpenWeatherMap API, Scikit-learn, Dask, and Matplotlib on the second code to build a comprehensive weather forecasting system. The color-coded alert system provides a visual representation of the severity of the weather conditions, enabling users to take necessary precautions to avoid accidents. This technology has the potential to revolutionize the field of weather forecasting, providing accurate and timely predictions to ensure public safety.
RDIDINI PROMPT ENGINEER
2 notes
·
View notes
Text
Meet The Woman Who Made Polaroid Into A Cultural Icon
Meroë Marston Morse, an Art History Undergraduate, Led and Transformed the Camera Company into a Brand Beloved by Photographers to This Day.
— By David M. Barreda | March 27, 2024

Meroë Marston Morse joined Polaroid just weeks after graduating from Smith College—and quickly rose to become one of the iconic company's most visionary leaders. She's seen here in a test photograph taken by Polaroid laboratory staff in the 1940s. Polaroid Corporation Records, Baker Library, Harvard Business School
Polaroid. The Tconic Camera brought photography into the hands of millions beginning in the 1940s. It made anyone a photographer with a push of a button, developing the pictures right in front of your eyes.
At a time when camera innovation was led almost exclusively by men, Polaroid was different in another way too: During her relatively short time at the company, a young art history grad named Meroë Marston Morse was one of Polaroid’s most important visionaries, ultimately rising to be director of the Special Photographic Research Division with 18 patents to her name.
As a senior photo editor at National Geographic, I have had a lifelong love for photography. Since I was a child, I remember watching family members use Polaroids to record the mundane moments of a vacation, while I used a Nikon camera with 35mm film. But when a photographer friend later showed me how to use a toothpick to push the dyes of a Polaroid that was mid-development—resulting in a more painterly, more impressionistic final image—I became a fan.
I know a fair bit about Polaroid and its founder, Edwin Land. But when I read Morse’s name for the first time recently, I was intrigued to learn more about role she played during her two decades there.
A New Kind of Camera Company
Morse joined Polaroid in 1945 just weeks after graduating from Smith College, having studied art history with Clarence Kennedy. A friend and associate of Edwin Land, Kennedy often recommended his best students to work at the camera company.

American scientist and inventor Edwin Herbert Land demonstrates his instant camera or Land Camera, manufactured by Polaroid, circa 1947. Photograph By Sam Falk, The New York Times/Redux
For Land, Morse became “a soul mate, a work mate, and a protector,” writes Victor K. McElheny in his biography of Edwin Land, Insisting on the Impossible. Morse was a natural to the Polaroid method, which McElheny quotes one of the company’s inventors as saying was, “to propose the hypothesis, to test the hypothesis, to modify the hypothesis, to test with another experiment—a sequential train moving at high speed, several hypotheses and experiments per hour.”
A few short months after her arrival, Morse was managing the black-and-white film division, where she led her team through round-the-clock shifts to transition the company away from monochromatic sepia prints to truly black and white Polaroid films.
The process was full of challenges. Not only did the crystals in the darkest areas of a print become reflective, but the paper they used collected fingerprints easily. Perhaps worst of all, some of the prints would fade after a few months. Chris Bonanos, whose book Instant documents the camera company’s history, writes that Land called the creation of black-and-white film “among the toughest things Polaroid ever pulled off.”
And Morse was at the center of it all, former Polaroid employees John and Mary McCann told me on a recent call. Morse’s team would analyze tiny incremental variances from a standard exposure Mary said, and Morse herself “had an eye for these differences” thanks to her art history training. “She and Land built it from the first experiments in the lab, all the way through the billion-dollars-worth of film they sold,” John adds.
A Marriage of Science and Art
John McCann tells me his time at Polaroid reminded him of the Renaissance, when “the best scientists were the best painters, and they did everything.” Artists at Polaroid were integral to science and experimentation, and their perspectives were as important as those of trained chemists.
Within Morse’s lab, there was a strong dedication to making technology to suit artists. She served as the liaison between scientists and the photographers who consulted for the companies—building relationships with fine art photographer Minor White, color art photography pioneer Marie Cosindas, and landscape photographer Ansel Adams.

Photographer Ansel Adams consulted with Polaroid in various capacities. In a letter to Morse in 1953, he complained about the company’s ads, which he said had, “served to place emphasis on the casual, amateur use of the camera and process which has, I think, minimized the more important aspects. Most people think of it as a semi-toy.” Photograph By Emmanuel Dunand, AFP/Getty Images
Adams was already a well-established, large-format, black-and-white photographer by the time he began to consult for Polaroid in 1948. His image, Monolith, the Face of Half Dome, Yosemite National Park, made in 1927, had landed him on the photography map. Yet Adams was very interested in Polaroid’s technology, particularly the cameras and the black-and-white film that Morse was developing. The two were in nearly constant contact.
Adams helped establish a process that photographers in the field used for feedback long before the advent of the digital camera: He would take a Polaroid to test the composition and exposure of an image before making a final image on the negative.
Legacy
Morse died from cancer in 1969 at the age of 46, before Polaroid had expanded into a global brand and cultural touch point, before the toy camera craze had peaked, and long before Polaroid filed for bankruptcy in 2001.
In a companywide memo announcing her passing, Polaroid executive Richard Young wrote, “To those who knew and loved Meroe, our lives were enriched and enlarged. Her kindness, concern and interest in everyone were exceeded by her generosity.”
By the 1970s and 80s, other camera companies started to emulate Polaroid’s point-and-shoot approach and aesthetic. In the late 2000s, photographers around the world went into mourning when the last Polaroid films hit their expiration dates after the company’s bankruptcy.

"9-Part Self Portrait," a collage of large-format Polapan prints by artist Chuck Close, is displayed at Sotheby's during a preview of The Polaroid Collection, a collection of fine art photographs that Land launched in the 1940s. Morse was key to building the company's relationships with artists in the collection. Photograph By Emmanuel Dunand, AFP/Getty Images
But in early 2008, as the last factories were winding down, Polaroid enthusiasts Florian ‘Doc’ Kaps and André Bosman raised over half a million dollars to rescue the factories, the film, and most importantly the chemistry knowledge of the company—and eventually they brought Polaroid film back to market.
Today, in a photography world where digital is king, the spirit that Morse and others brought to the company still lives on for photographers everywhere.
6 notes
·
View notes
Text
Getting Machine Learning Accessible to Everyone: Breaking the Complexity Barrier

Machine learning has become an essential part of our daily lives, influencing how we interact with technology and impacting various industries. But, what exactly is machine learning? In simple terms, it's a subset of artificial intelligence (AI) that focuses on teaching computers to learn from data and make decisions without explicit programming. Now, let's delve deeper into this fascinating realm, exploring its core components, advantages, and real-world applications.
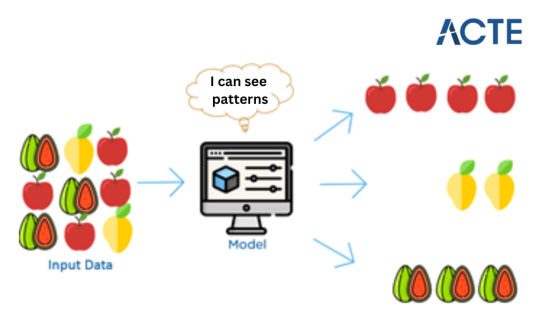
Imagine teaching a computer to differentiate between fruits like apples and oranges. Instead of handing it a list of rules, you provide it with numerous pictures of these fruits. The computer then seeks patterns in these images - perhaps noticing that apples are round and come in red or green hues, while oranges are round and orange in colour. After encountering many examples, the computer grasps the ability to distinguish between apples and oranges on its own. So, when shown a new fruit picture, it can decide whether it's an apple or an orange based on its learning. This is the essence of machine learning: computers learn from data and apply that learning to make decisions.
Key Concepts in Machine Learning
Algorithms: At the heart of machine learning are algorithms, mathematical models crafted to process data and provide insights or predictions. These algorithms fall into categories like supervised learning, unsupervised learning, and reinforcement learning, each serving distinct purposes.
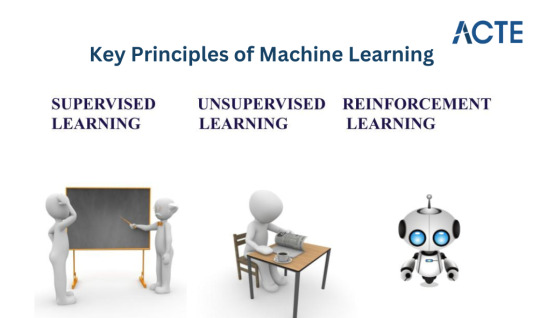
Supervised Learning: This type of algorithm learns from labelled data, where inputs are matched with corresponding outputs. It learns the mapping between inputs and desired outputs, enabling accurate predictions on unseen data.
Unsupervised Learning: In contrast, unsupervised learning involves unlabelled data. This algorithm uncovers hidden patterns or relationships within the data, often revealing insights that weren't initially apparent.
Reinforcement Learning: This algorithm focuses on training agents to make sequential decisions by receiving rewards or penalties from the environment. It excels in complex scenarios such as autonomous driving or gaming.
Training and Testing Data: Training a machine learning model requires a substantial amount of data, divided into training and testing sets. The training data teaches the model patterns, while the testing data evaluates its performance and accuracy.
Feature Extraction and Engineering: Machine learning relies on features, specific attributes of data, to make predictions. Feature extraction involves selecting relevant features, while feature engineering creates new features to enhance model performance.
Benefits of Machine Learning

Machine learning brings numerous benefits that contribute to its widespread adoption:
Automation and Efficiency: By automating repetitive tasks and decision-making processes, machine learning boosts efficiency, allowing resources to be allocated strategically.
Accurate Predictions and Insights: Machine learning models analyse vast data sets to uncover patterns and make predictions, empowering businesses with informed decision-making.
Adaptability and Scalability: Machine learning models improve with more data, providing better results over time. They can scale to handle large datasets and complex problems.
Personalization and Customization: Machine learning enables personalized user experiences by analysing preferences and behaviour, fostering customer satisfaction.
Real-World Applications of Machine Learning
Machine learning is transforming various industries, driving innovation:
Healthcare: Machine learning aids in medical image analysis, disease diagnosis, drug discovery, and personalized medicine. It enhances patient outcomes and streamlines healthcare processes.
Finance: In finance, machine learning enhances fraud detection, credit scoring, and risk analysis. It supports data-driven decisions and optimization.
Retail and E-commerce: Machine learning powers recommendations, demand forecasting, and customer behaviour analysis, optimizing sales and enhancing customer experiences.
Transportation: Machine learning contributes to traffic prediction, autonomous vehicles, and supply chain optimization, improving efficiency and safety.
Incorporating machine learning into industries has transformed them. If you're interested in integrating machine learning into your business or learning more, consider expert guidance or specialized training, like that offered by ACTE institute. As technology advances, machine learning will continue shaping our future in unimaginable ways. Get ready to embrace its potential and transformative capabilities.
#machine learning ai#learn machine learning#machine learning#machine learning development company#technology#machine learning services
8 notes
·
View notes
Text
Revolutionizing Software Testing: The Comprehensive Benefits of Automation Testing with Selenium
In the ever-evolving landscape of software development, the role of testing is paramount to ensure the reliability and performance of applications. Automation testing, particularly with Selenium, has emerged as a game-changer, offering a plethora of benefits that streamline the testing process and contribute to the overall efficiency of software development. Embracing Selenium's capabilities becomes even more accessible and impactful with Selenium Training. This training equips individuals with the skills and knowledge to harness the full potential of Selenium, enabling them to proficiently navigate web automation challenges and contribute effectively to their respective fields. In this exploration, we delve into the comprehensive advantages of automation testing with Selenium and its transformative impact on the software testing ecosystem.

1. Time Efficiency: Accelerating Testing Processes
Automation testing with Selenium is synonymous with time efficiency. By automating the execution of test cases, Selenium enables testers to run multiple scripts simultaneously. This parallel execution across various browsers and platforms significantly reduces testing time compared to the sequential nature of manual testing. Time efficiency is a crucial aspect in the fast-paced world of software development, allowing teams to deliver products with speed and agility.
2. Reusability of Test Scripts: Maximizing Code Investment
One of the standout features of Selenium is the reusability of test scripts. Test scripts developed for specific scenarios can be easily adapted and reused for similar test cases. This modularity not only expedites script development but also enhances maintainability. The ability to reuse scripts across different scenarios contributes to code consistency and reduces duplication of efforts, ensuring an optimized and efficient testing process.
3. Consistency and Accuracy: Eliminating Human Errors
Automation testing eliminates the inherent risks associated with human errors in manual testing. Selenium ensures consistent and precise test execution, adhering to predefined test scenarios without deviations. This consistency is particularly vital for repetitive test cases and regression testing, where precision and accuracy are paramount. By minimizing the risk of human errors, Selenium enhances the reliability of test results.
4. Parallel Execution: Optimizing Resource Utilization
Selenium's compatibility with tools like Selenium Grid enables parallel execution of test scripts on multiple machines. This not only expedites test runs but also optimizes resource utilization. Test scripts can be simultaneously executed on different configurations, browsers, and platforms, ensuring efficient use of available resources. Parallel execution is a key factor in scalability, making Selenium a preferred choice for projects of varying sizes.
5. Faster Feedback in Continuous Integration (CI) Pipelines: Integrating Testing with Development
Automation testing seamlessly integrates with Continuous Integration (CI) pipelines, a fundamental aspect of modern software development practices. Selenium's compatibility with CI tools like Jenkins allows automated tests to be executed automatically with every code change. This facilitates faster feedback to developers, enabling early detection of bugs and ensuring a smoother integration process.
6. Comprehensive Test Coverage: Ensuring Thorough Validation
One of the inherent strengths of automation testing with Selenium is its ability to achieve comprehensive test coverage. Selenium scripts can cover a wide range of scenarios, including positive and negative test cases, edge cases, and various user inputs. This thorough validation ensures that applications are tested comprehensively, contributing to a robust and reliable software product.
7. Regression Testing: Validating Code Changes with Confidence
Selenium excels in performing regression testing, a critical aspect of software development, especially in agile environments. Automated scripts can quickly rerun test cases to validate that new code changes haven't adversely impacted existing functionalities. This rapid and consistent validation of code changes ensures that software updates are introduced with confidence and minimal disruption to existing features.
8. Cost Savings: Balancing Initial Investment with Long-Term Efficiency
While the initial setup and script development for automation testing may require an investment of time and resources, the long-term cost savings are significant. Automation testing with Selenium leads to increased efficiency, faster testing cycles, and reduced reliance on manual testing efforts. This results in a more cost-effective testing process over time, making it a prudent investment for organizations looking to optimize their testing workflows.
9. Cross-Browser and Cross-Platform Testing: Ensuring Compatibility Everywhere
Selenium's versatility shines in its ability to conduct cross-browser and cross-platform testing. Test scripts can be executed across various browsers (Chrome, Firefox, Safari, etc.) and platforms (Windows, macOS, Linux), ensuring that applications function consistently across diverse environments. This capability is crucial for reaching a broad user base with different preferences and devices.
10. Enhanced Test Report Generation: Facilitating In-Depth Analysis
Automation testing is not just about running tests; it's about gaining insights into the application's health. Selenium provides detailed and customizable test reports, offering valuable information on test execution results. Tools like TestNG and JUnit enhance reporting capabilities, aiding in comprehensive test result analysis. This visibility into test outcomes enables teams to make informed decisions and prioritize areas that require attention.
11. Scalability: Adapting to Project Growth
Selenium's scalability is a key attribute that makes it suitable for projects of varying sizes. As a project evolves, additional machines can be seamlessly integrated as nodes in the Selenium Grid. This scalability ensures that automation testing remains efficient and effective, regardless of the project's growth trajectory.
12. Improved Test Maintenance: Adapting to Changing Application Landscapes
In the dynamic world of software development, applications undergo frequent changes. Selenium excels in adapting to these changes, making test maintenance more straightforward. When there are updates or modifications in the application, corresponding adjustments can be made efficiently to the automated scripts. This agility in test maintenance is crucial for ensuring that automated tests remain aligned with the evolving application landscape.
In conclusion, automation testing with Selenium is a transformative force in the realm of software testing. Its comprehensive benefits, ranging from time efficiency and reusability to scalability and improved test maintenance, make it an indispensable tool for modern software development practices. As organizations increasingly prioritize agility, efficiency, and reliability in their development processes, Selenium stands out as a cornerstone in achieving these objectives. Embracing automation testing with Selenium not only accelerates the testing lifecycle but also contributes to delivering high-quality software products that meet the demands of today's dynamic and competitive market. To unlock the full potential of Selenium and master the art of web automation, consider enrolling in the Top Selenium Training Institute. This training ensures that individuals gain comprehensive insights, hands-on experience, and practical skills to excel in the dynamic field of web testing and automation.
2 notes
·
View notes
Video
youtube
Kanban, Waterfall, and DevOps are three different approaches to project management and software development. Here's an overview of each concept: 1. Kanban: Definition: Kanban is a visual management method for software development and knowledge work. It originated from manufacturing processes in Toyota and has been adapted for use in software development to improve efficiency and flow.
Key Concepts: Visualization: Work items are represented on a visual board, usually with columns such as "To Do," "In Progress," and "Done."
Work in Progress (WIP) Limits: Limits are set on the number of items allowed in each column to optimize flow and avoid bottlenecks.
Continuous Delivery: Focus on delivering work continuously without distinct iterations.
Advantages: Flexibility in responding to changing priorities.
Continuous delivery of value. Visual representation of work enhances transparency.
Use Case: Kanban is often suitable for teams with variable and unpredictable workloads, where tasks don't follow a fixed iteration cycle.
2. Waterfall: Definition: The Waterfall model is a traditional and sequential approach to software development. It follows a linear and rigid sequence of phases, with each phase building upon the outputs of the previous one.
Phases: Requirements: Define and document project requirements. Design: Create the system architecture and design. Implementation: Code the system based on the design. Testing: Conduct testing to identify and fix defects. Deployment: Deploy the completed system to users. Maintenance: Provide ongoing support and maintenance.
Advantages:
Clear structure and well-defined phases.
Documentation at each stage.
Predictable timelines and costs.
Disadvantages: Limited flexibility for changes after the project starts.
Late feedback on the final product.
Risk of customer dissatisfaction if initial requirements are misunderstood.
Use Case: Waterfall is suitable for projects with well-defined requirements and stable environments where changes are expected to be minimal.
3. DevOps: Definition: DevOps (Development and Operations) is a set of practices that aim to automate and improve the collaboration between software development and IT operations. The goal is to shorten the development lifecycle, deliver high-quality software, and foster a culture of continuous integration and delivery.
Key Practices: Continuous Integration (CI): Merge code changes frequently and automatically test them.
Continuous Delivery/Deployment (CD): Automate the release and deployment processes.
Collaboration: Promote collaboration and communication between development and operations teams.
Advantages: Faster delivery of software. Reduced manual errors through automation. Improved collaboration and communication.
Use Case: DevOps is suitable for organizations aiming to achieve faster and more reliable delivery of software through the automation of development, testing, and deployment processes.
#mktmarketing4you #distributionchannels #HoshinPlanning #Leanmethods #marketing #M4Y #lovemarketing #IPAM #ipammarketingschool #Kanban #ContingencyPlanning #virtual #volunteering #project #Management #Economy #ConsumptionBehavior #BrandManagement #ProductManagement #Logistics #Lifecycle #Brand #Neuromarketing #McKinseyMatrix #Breakevenanalysis #innovation #Facebook #icebergmodel #EdgarScheinsCultureModel #STARMethod #VRIO #7SFramework #gapanalysis #AIDAModel #SixLeadershipStyles #MintoPyramidPrinciple #StrategyDiamond #InternalRateofReturn #irr #BrandManagement #dripmodel #HoshinPlanning #XMatrix #backtobasics #BalancedScorecard #Product #ProductManagement #Logistics #Branding #freemium #businessmodel #business #4P #3C #BCG #SWOT #TOWS #EisenhowerMatrix #Study #marketingresearch #marketer #marketing manager #Painpoints #Pestel #ValueChain # VRIO #marketingmix We also left a video about Lean vs Agile vs Waterfall | What is Lean | Difference between Waterfall and Agile and that could help you. Later we will leave one about Kanban:
2 notes
·
View notes
Text
hmmm…so like in C++(20) I need to do two things right now. ok—I wrote this post and it turned out to be 4! (4. Not 4!. Thankfully.) C++ coding diary/questions/difficulties below:
The recursive function I’m working with is structurally the following:
void f(x) {
if(cond) {
successCode
} else {
code1; f(g(x));
if(cond2) { code2; f(h(x)) }
}
}
So, it can either call itself with different arguments—possibly twice, one after the other—or it can succeed.
The way it works, though, is by having code1 and code2 update entries in a global array. (In fact, code1 is simply a[something] = a[somethingElse], and code2 is simply a[something] = 1. cond2 is a[somethingElse] == 0.) So we do have to proceed sequentially to some extent.
Ideally, successCode initiates a possibly computationally intensive task on, say, one of my CPU cores, but spins that off and continues on with the recursive call. However, successCode needs to only spin that process off after it’s finished reading from that global array. (Maybe that part will be trivial.) Further, it needs to stall in the case too many of these processes have been spun off already, and wait for there to be an opening to start.
I’m wondering if std::thread has what I need for that.
2. one thing I’m doing which feels “bad” is: well, I need to have some local constants accessible to a recursive function. Right now I’m essentially just calling f(a, x) where a is unchanged across recursive calls and x changes. Does the compiler know how to handle this correctly…? Is there a better way? Like making a class or something? (I would typically just define this recursive function f(x) inside an outer function that took a as an argument, but you can’t do that directly in C++…)
3. another which feels bad is using this global array! I just need a block of memory whose length is fixed for the majority of the time, but which must be (rarely) grown. does a std::vector give me just as good performance as a really long array, I wonder? The main thing I’m doing is accessing and setting bits at a bunch of different indices, not inserting or growing…and it never grows too large, so maybe a long array is fine.
4. And that’s the other problem—I’m setting bits. that means I get to choose between:
a long (~100?) (and mostly empty most of the time) global array of bools (current, default choice)
the rumored-to-be-cursed std::vector<bool>, which is overridden to be space-efficient instead of a vector of bools—but at the cost of a bunch of its vector-ness! is it better? who knows! half the things on the manual page say “eh, we leave it up to the implementation to decide how or even whether to do this.”
a long and mostly empty most of the time bitset
a boost::dynamic_bitset, which is like a bitset but…dynamic…and I don’t know if that’s better. Like I said I don’t really need to grow it.
what if I just had as many unsigned ints as I needed and manipulated their bits with bitshifting somehow, as though the concatenation of the ints were my array. what then. would that be far worse?
The weird thing is that I don’t need space efficiency, but I do, on each success, need to transform (and alter) the content of this array (or whatever) into something which is space-efficient, but in a weird and bespoke way (I use the last 6 bits of bytes). that means im either constantly converting integer indices into (whichByte, whichBit) pairs and accessing/setting bit values in bytes at the result, or I’m doing one single translation of the whole array each successCode. hard for me to say which is more efficient without testing…but the second *seems* better somehow. but integer operations might be really fast. idk.
2 notes
·
View notes